1. sequential decision problem
- sequential decision problem이란, 매 시간 t마다 agent가 observation을 input으로 받아서 action을 선택하는 문제이다.
- policy는 어떤 action을 할지 결정하는 함수
- fully-observable할 때는 observation 대신 state라고 함. 우리는 optimal policy를 찾기위해서 observation인지 state인지 구분하는 것이 중요하다. state는 conditional independence를 만족하지만, observation들은 만족하지 않기 때문이다. conditional independence를 만족하는 state는 markov property를 만족한다. fully-observable하지 않은 상태에서는? 좋은 Policy찾기 위해서는 history 정보도 고려해주어야 한다.
- bayes network(probabilistic graphical model로 시각화)

2. Imitation Learning
- imitation learning = supervised learning = behavioral cloning
- 자율주행 예시
자동차에 전방 카메라를 부착해서 학습데이터를 생성한다. 운전자가 주행을 하면서 카메라의 화면이 observation이 되고, 핸들의 방향을 action으로 한다. supervised learning 방식을 통해서 training data로 policy를 학습한다. 여기서 문제점은 distributional drift이다. Model이 실수를 한다면, Model이 보지 못했던 observation을 보게되고 좋지 않은 action을 선택하게 되고 오류가 반복적으로 누적된다. 해결방법은, 1)heuristic trick을 통해서 학습하면 보완이 된다. NVIDIA는 좌측,우측 전방에 카메라를 더 설치하고 좌측 카메라의 action(label)에는 우측을 bias로, 우측 카메라의 action(label)에는 좌측을 bias를 주어 training data를 만들었다.
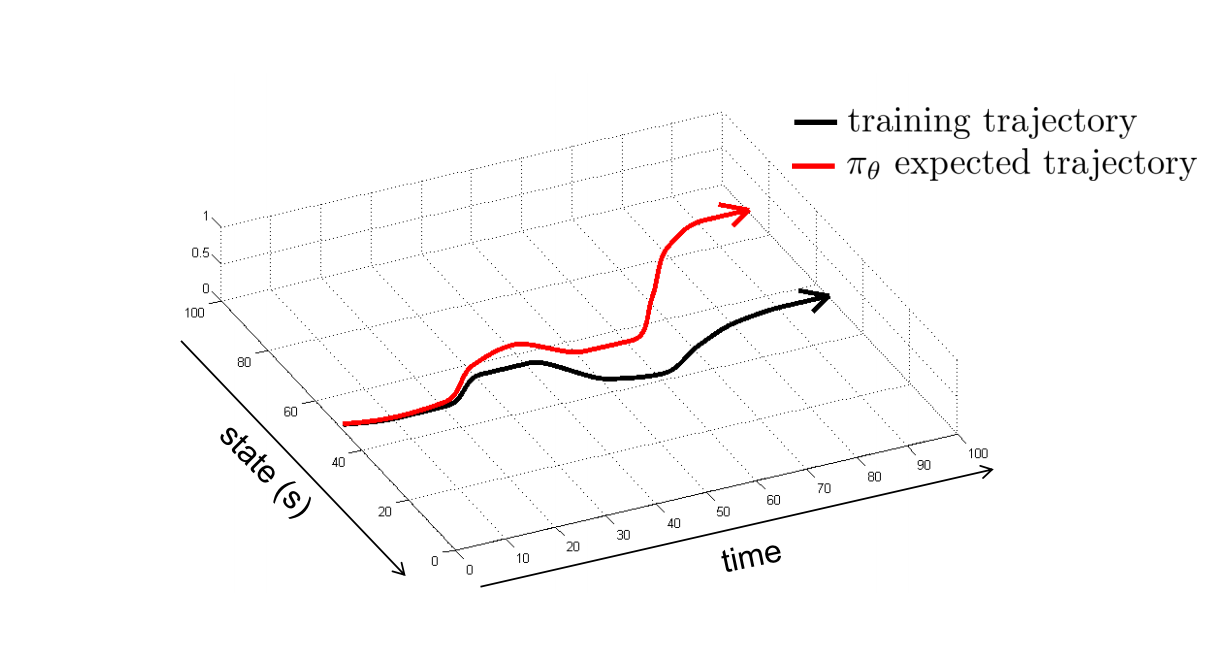
해결방법 2) DAgger는 heuristic trick보다 general algorithm 해결방법이다.
- 기존 policy를 통해서 테스트해보면서 데이터를 수집하고 도메인 전문가를 통해 action에 라벨을 부여하는 것이다.
- Theoretical Analysis
policy가 실제 학습데이터와 mismatch가 일어날 확률의 upper bound를 정의, mismatch가 일어날 때마다 1이라는 cost가 발생한다.- 1. state distribution 정의
- 2. policy가 mismatch가 일어날 확률
- 3. mismatch가 일어날 때의 cost 정의
- 4. distribution에서 cost의 expectation의 upper bound를 계산하고 비교
- timestamp t까지 mistake가 발생하지 않았을 때와 mistake가 발생했을 때,
behavioral cloning은 quadratic하게 cost가 증가하므로 DAgger의 성능 향상 확인 가능
3. Case studies of deep imitation learning
DAgger를 통해서 성능향상은 가능하지만, 전문가의 라벨링이 필요하다는 한계가 있다.
학습 초기에 training trajectory에서 크게 벗어나지 않게 하는 방법에 대해서 알아보자.
모델 학습의 방해요소로,
1) non-markovian behavior
markov property를 만족하지 않는 경우인 state가 아니라 observation이 input으로 들어가는 경우에는 history까지 고려를 해주어야 한다.
문제점은 모든 history가 들어가면 input의 크기가 너무 커진다.
해결방법은 LSTM과 같은 시계열 데이터에서 memory역할이 되는 모델을 사용하면 된다.
history 정보를 사용할 때 문제점은, causal confusion(인과관계를 올바르게 연결짓지 못하는 문제)이 심해질 수 있다.
예를 들어, 보행자가 보일 때 브레이크를 밟는데, 브레이크를 밟을 때마다 노란 불이 들어오는 자동차이다. 이 자동차가 학습한 모델은
(보행자가 보인다 → 브레이크를 밟는다 → 노란 불빛이 들어온다)라는 함수는
(노란 불빛이 들어온다 → 브레이크를 밟는다)라는 인과관계로 잘못 학습될 수 있다.
2) multi-modal behavior
왼쪽으로 가는 방법과 오른쪽으로 가는 방법 두가지가 있다. gaussian function을 policy 함수로 사용한다면, 문제점은 중앙으로 돌진하는 action이 발생할 수 있다.
해결방법은 gaussian mixture model을 사용해서 왼쪽으로 가는 policy와 오른쪽으로 가는 policy를 학습하는 것이다.
policy function이 복잡하다면? action space를 discretize하는 것이 방법이 될 수 있지만, 문제점은 action의 dimension이 크다면, action space는 exponential하게 증가할 것이다. (옳은 방법이 아니다.)
해결방법은 각 action의 dimension을 Independent하게 학습하는 것이다. 방법으로 auto-regressive discretization은 dimension별로 discretize한 후, sampling한 action을 통해서 다음 dimension의 action을 선택하는 것이다.
추가적으로 unsupervised method로 latent variable model(variable auto-encoder)로 학습된 weight를 initialization point로 활용될 수 있다.