이전에 CNN 모델의 결과를 정성적 평가해보니 문맥이 고려되지 않고 키워드를 기반으로 fake news를 분류하고 있었다.
그래서 문맥 가능한 모델로 디벨롭을 해보고자 어텐션과 ELMo 임베딩, BERT에 대해서 스터디를 하고 우리 모델에 적용해보기로 하였다!
1. seq2seq의 문제점1
seq2seq의 encoder에서 context vector 하나에 모든 정보를 압축하려다보니 정보손실의 문제가 발생
2. seq2seq의 문제점2 : RNN 기울기 소실
- RNN 계층이 과거 방향으로 '의미 있는 기울기'를 전달함으로써 시간 방향의 의존 관계 학습 가능
- 기울기는 학습해야 할 의미 있는 정보가 들어있음. 과거로 전달하여 장기 의존 관계를 학습하는데, 기울기가 소실되면 과거의 정보 학습이 어려워짐. 그래서 장기 의존 관계를 학습할 수가 없게 됨.
- 장기 의존 관계란?
Tom was watching TV in his room. Mary came into the room. Mary said hi to ?
?에 들어갈 단어를 예측하려면 'tom이 TV를 방에서 보고 있다.'와 'Mary가 방에 들어온다'라는 정보들을 기억해야지 뒤의 내용이 예측이 가능함. 이러한 정보들을 장기 의존 관계라고 함.
3. 어텐션 메커니즘 간단하게 정리하기
(배경지식)우선 seq2seq는 encoder와 decoder로 이루어져있고 encoder에서 나온 마지막 hidden state가 context vector가 되고 context vector는 input으로 들어온 텍스트의 전반적인 내용을 잘 담고있는 벡터야. 이 벡터가 decoder로 들어가면서 한단어씩 다음 단어로 들어올 단어를 예측하는 방식으로 학습이 돼!
- 어텐션 메커니즘을 왜 쓰는거야?
seq2seq모델에서 encoder의 마지막 hidden state가 context vector는 정보 손실과 장기 의존성 문제를 가지고 있어.
정보가 손실된 context vector가 decoder에 들어가게 되면 다음 단어를 예측하는 데에 잘못된 예측을 하겠지.
그러면 어떻게 해야 다음 단어를 잘 예측할 수 있을까? 우리가 다음 단어를 예측할 때 input text중 집중(attention)해야할 부분을 알려주면 더 잘 예측할 수 있겠지?
- 난 어텐션 모델로 착각했었는 데 그건 아마 트랜스포머 구조를 너무 많이 들어서 그런 거 같아. 트랜스포머가 self-attention을 하는 layer를 가지고 있거든!
- 어텐션 메커니즘은 어떤식으로 사용하는 거야?
잠깐 내가 짠 모델을 보여주면 왼쪽에 biLSTM보여?? biLSTM의 hidden state들을 기반으로 attention score기반의 context vector를 만들어서 사용하는 거야~~ 내가 하고있는 프로젝트에서 이 전 모델의 문제점이 context를 잘 반영하지 못하는 거였거든,, keyword만 잘 반영했어서 그걸 보완하고 싶어서 attention을 넣게되었어~!
encoder-decoder구조에서는 encoder의 context context vector로 사용해서 decoder가 더 잘 예측할 수 있도록 만들어주겠지!

- 어텐션은 어떻게 작동하는 거야?
간단하게 알려주면, 우선 encoder의 time step마다 hidden state(각 단어가 들어갈 때마다 업데이트 된 hidden state)가 다 필요해.
그러고 decoder의 현재 hidden state도 필요해~~ 왜냐면 decoder hidden state와 encoder의 각 hidden state를 비교해서 지금 어디에 집중(attention)해야하는지를 점수로 나타낼 거 거든!
1. attention score
어텐션 스코어를 구하는 방법에 따라서 어텐션 이름이 달라지는데(ex. 루옹어텐션, 바다나우 어텐션) 루옹어텐션이 가장 쉬워서 이거로 예를 들어볼게. 현재 time step에서 다음 단어를 예측하기 위해 현재 decoder의 hidden state와 encoder의 각 hidden state가 얼마나 유사한지를 score로 내!☑️

t : time step
i : encoder의 몇번째 time step의 hidden state인가
2. attention weight
softmax를 통해서 score값들을 다 더했을 때 1이 나오도록 해. softmax를 거친 후 값 하나씩을 weight라고 해~!

ex) [I, am, a, student] = [0.4, 0.1, 0.1, 0.4]
3. attention value
위에서 구한 각 인코더의 attention weight와 hidden state를 가중합해주는 과정이야.
각 인코더의 문맥을 포함하고 있어서 context vector라고도 해~! encoder의 마지막 hidden state를 context vector로 사용했었지? 그걸 대신해서 사용해도 돼!

4. attention value와 decoder t시점의 hidden state 연결하기
concatenate하는 과정이야. attention value(context vector)랑 t시점의 hidden state를 그대로 붙여주면 돼
5. 출력층 들어가기 위한 입력값 만들어주기
신경망을 추가해서 tanh에 넣어주었어🤓. 우리가 다음 단어를 예측할 때 decoder의 hidden state가 들어가는데, 그거 대신에 이번에 구한 벡터를 넣어줄거야

6. 출력층으로 슈슈슉
출력층에 넣어서 예측 벡터를 얻어보자🤓

4. ELMO 란?
동음이의어에 대한 구별을 하기 위해서 나온 임베딩 방법론 : '사과'가 과일의 의미로 쓰일 수도 있고 '미안하다'라는 의미로 쓰일 수도 있는데 이것은 어떤 문장에서 사용됐는지를 알면 충분히 구별이 가능하다. 전체 문장을 고려해서 임베딩을 하겠다는 의미로 contextualized word embedding이라고 한다.
ELMo는 RNN기반의 Language model(LSTM)으로 pre-training한다. 대신 순방향모델과 역방향모델 따로 모두 학습하며 multi-layer를 가진다. LSTM모델의 Input으로는 char CNN으로 워드 임베딩이 이루어진다.
<ELMo 학습하는 방법>
1. charCNN 워드임베딩 후 LSTM의 input으로 들어감
➡️ OOV(out of vocabulary)에 견고함 :
2. 순방향 LM(Language Model), 역방향 LM에서 학습. 다층구조를 가짐(multi-layer)
3. 순방향 출력값과 역방향 출력값들을 각 층별로 concatenate해줌.
(ex. L1 = forward layer1+backward layer1
L2 = forward layer2+backward layer2
L3 = forward layer3+backward layer3)
➡️ 각 층의 출력값은 서로 다른 종류의 정보를 갖고 있을 것이다.
4. 각 concatenate 결과에 가중치를 줌.(ex. s1,s2,s3)
5. 가중합을 통해 single vector구함 (s1 * L1 + s2 * L2 + s3 * L3)
6. 벡터값의 스케일링을 위한 스칼라 매개변수를 곱해줌
5. BERT란?
- BERT는 Language Representation을 해결하기 위해 고안된 구조이다. 그래서 Transformer Architecture에서 encoder로 이루어진 구조임. 단어, 문장, 언어에 대한 표현을 더 잘한다면 task를 더 잘 해결할 수 있을 것임!
- BERT는 양방향성 특징을 가지는 데, 문장을 앞에서 뒤로 뒤에서 앞으로 이해하면 전체적인 문맥을 이해할 수 있음. (LSTM보다 biLSTM이 전체적인 문맥을 더 잘 이해하는 것과 유사). 예를 들어, '잘했다'가 긍정적인 의미로도 쓰일 수 있고 부정적인 의미로도 쓰일 수 있는데 이것을 반영할 수 있는 모델이라는 것이다.
- 대용량 corpus에 의해 pre-training이 되고 task에 transfer하여 fine-tuning이 이루어진다.
- BERT는 어떻게 학습되나요?
1) 우선 BERT의 input 형태는 어떻게 되나요?
Tokenization은 word piece이고 세가지 임베딩(token, segment, position)으로 문장을 표현한다.
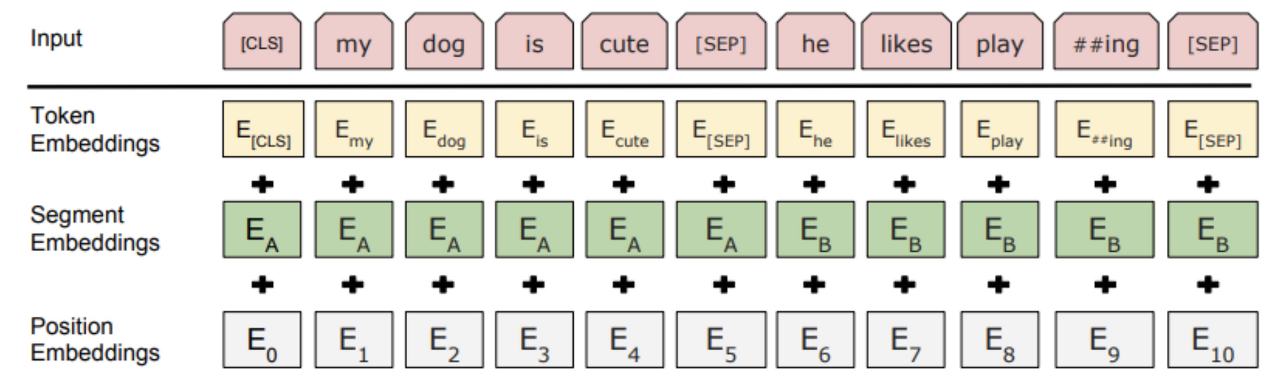
1)token embedding : word piece이고, <CLS>:문장 시작, <SEP>:문장 종료 으로 문장을 구별
2)position embedding : 각 토큰의 위치를 알려줌
3)segment embedding : 문장의 구분. pre-training시에 두 문장이 연관되어 있는가에 대해서 학습하게 되는데 이때 사용된다.
2) 이후 두가지 방법으로 pre-training을 시킨다.
1️⃣ Masked Language Model : [Mask]로 단어를 가려서 [Mask]단어를 예측하기
➡️ BERT의 문맥파악 능력을 기르게 함
➡️ 다양한 표현 학습을 위해, 80%는 [Mask] 토큰으로, 10%는 random word로, 10%는 원본 word로 대체
2️⃣ Next Sentence Prediction : 두 문장 사이의 관계, 관련이 있는 문장(IsNext Label)인가? 관련 없는 문장(NotNExt Label)인가?
➡️ QA와 NLI task 향상
<참고자료>
https://velog.io/@changdaeoh/ELMointro
https://hwiyong.tistory.com/392
<이전 글>
2022.04.01 - [분류 전체보기] - [캡스톤] 3월 4주차 trial and error
[캡스톤] 3월 4주차 trial and error
1. CNN architecture를 생각하기가 어렵다.. 어떻게 하는게 좋을까... CNN의 convolution layer + pooling layer를 통해서 주변단어를 같이 보는 효과를 주기 때문에 title과 body input-embedding후 둘을 concat..
whatsbird-story.tistory.com
'Project 🖥 > 2022 캡스톤👩🏻💻' 카테고리의 다른 글
| [캡스톤] 4월 3주차 trial and error (0) | 2022.04.16 |
|---|---|
| [캡스톤] summarization 흐름 파악 (0) | 2022.04.09 |
| [캡스톤] 3월 4주차 trial and error (0) | 2022.04.01 |


