1️⃣ Pre-trained Distillation > Pre-training + fine-tuning
- pretraining(unlabeld LM data) → Distillation(unlabeled transfer data) → fine-tuning(labeled data) → Final Compact Model
- 이전에는 heuristically initialized student로 시작했는데, 이번 연구는 pre-trained를 통해서 초기화해줌
2️⃣ statement
- the teacher : 높은 정확도를 가지지만 사이즈가 큰 모델. 리소스 제한이 있으면 사용하기 어렵다..🥺
- students : 리소스 제한이 있을 때, 모델 사이즈를 상대적으로 조정해서 컴팩트하게 사용할 수 있는 모델
- labeled data $D_L$ : training examples
- unlabeled transfer data $D_T$ : labeled set과 비슷한 분포를 가지고 있는 데이터셋, labeled data의 일부를 포함하고 있을 수 있음.
- unlabeled language model data $D_{LM}$ : MLM objective로 unsupervised learning을 진행함.
3️⃣ pre-trained distillation (PD)
- pre-training on D_LM : masked LM objectives
- Distillation on D_T : soft labels (predictive distribution) produced by teacher
- pre-training step이 덜 완벽한 transfer set으로 인해 오히려 잘못된 방향으로 학습될 수 있음.
- fine-tuning on D_L : model을 robust하게 만들어주는 부분(transfer set이랑 labeled set의 분포가 안맞아도 유효한 모델이 도리 수 있게)
4️⃣ Dataset

5️⃣ Experiement
- model size : 4m ~ 110m parameters
- amount/quality of unlabeled data : labeled set과의 유사도뿐만 아니라 양까지 실험함.
6️⃣ Analysis
우선, pre-trained input representation / shallow-and-wide students from the bottom layers of their deep pre-trained counterparts 방법들이 있음.
- pre-train 워드 임베딩으로 충분한가? 아-니. pre-trained layer를 함께 사용하는 것보다 24% 덜 distillation 됨.
- pre-trained model을 잘라서 사용하는 것이 더 안좋은가? shallow students에는 해당하는 얘기다.

3. 파라미터 개수가 고정되어 있다면 무엇이 가장 좋은 student임?
파라미터가 많을수록 당연 좋은 모델이긴함.. width보다는 depth가 더 효과적임. 6L/512H가 2L/768H보다 더 좋은 성능을 보여줌.

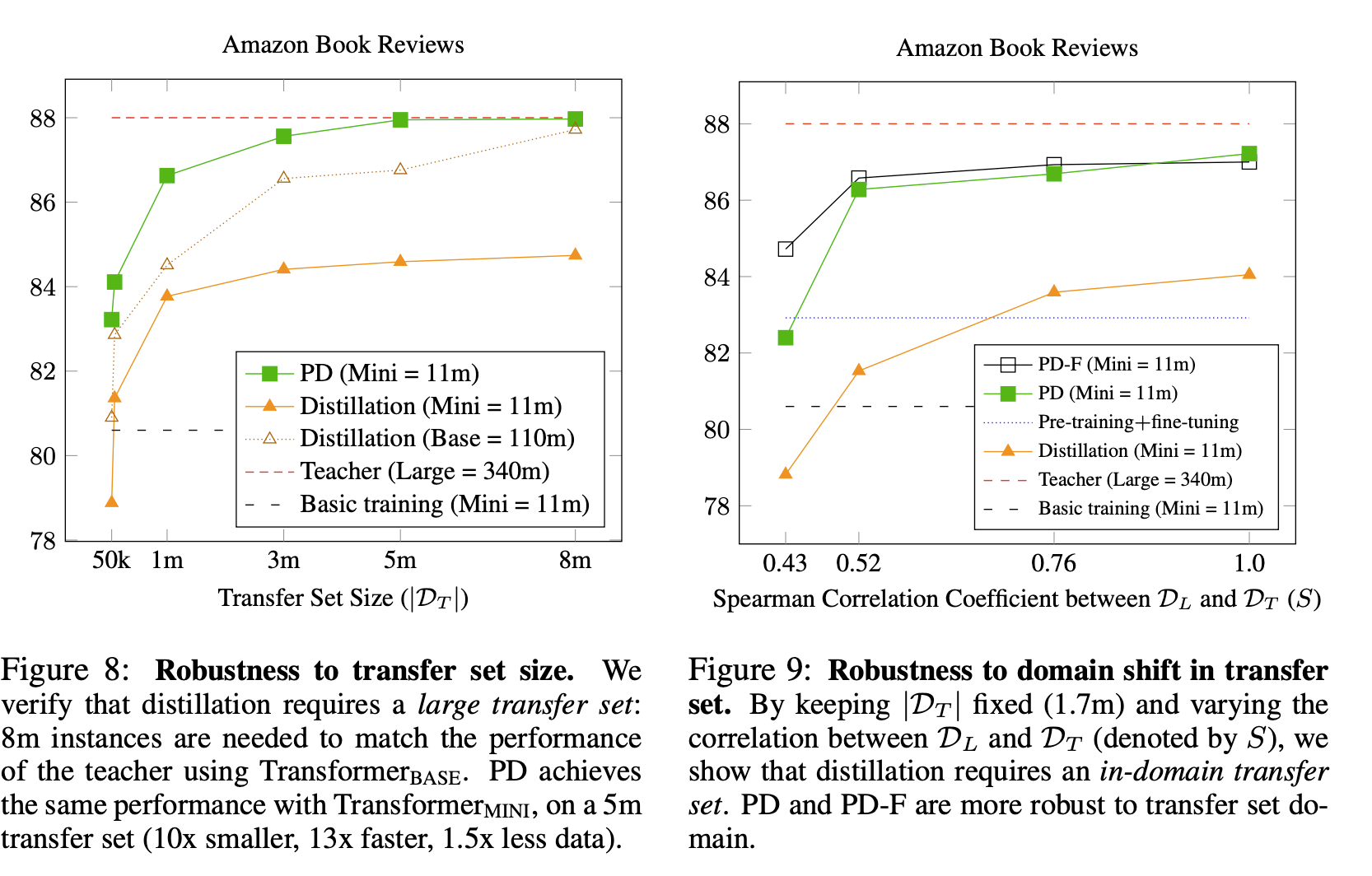
4. robustness to transfer set size & robustness to domain shift in transfer
- PD는 5m정도, distillation은 8m정도면 좋은 성능을 냄. PD가 distillation보다 1.5배 더 적게 데이터가 필요함
- pre-train set 도메인과 transfer set 도메인의 차이정도를 spearman correlation coefficient로 구해보았고, PD와 PD-F(PD + fine-tuning)가 distillation보다 domain에 robust함~~!!
5. Better Together🤝
- pretraining과 distillation사이의 interaction이 동일한 데이터에서 어떻게 보이는지 살펴봅시당
- 아래 그래프 보면 PD가 PF보다 평균적으로 2.2%정도 더 좋은 성능을 보이고 있음.

- 비교
- Patient Knowledge Distillation : deeper pre-trained model에서 가장 아래 layer로부터 student model을 초기화함. teacher와 student의 아키텍처에 대한 가정을 해야함.
- DistilBert : truncation method → 더 비싸고 빵빵한 LM teacher로부터 distiallation으로 pre-training → fine-tuning
'everyday paper📃' 카테고리의 다른 글
| sentence embedding (2) | 2023.01.25 |
|---|---|
| [ACL 2021]Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence (0) | 2022.08.04 |
| [neurIPS 2021] Pay Attention to MLPs (0) | 2022.07.08 |

